The Bookstore Walkthrough
In this chapter you will gain an understanding of the process from idea to a live Bookstore search engine, including implementation of a wide range of Panl functionality:
- DATE Range facets,
- BOOLEAN facet checkboxes,
- Passthrough parameters,
- REGULAR Multivalued separator facets,
- Specific Solr Search Field keyword searches,
- More Like This results return
- (Optional configuration for highlighting)
At this point, you should
- Have read the Panl Fundamentals and Solr Fundamentals chapter .
- Have a functional Solr server with at least the mechanical pencils dataset indexed.
- Have a good understanding of how to add data to the Solr server (the Additional Data section has more information).
- Have a Panl server instance available and have looked at the functionality provided.
- Also have a good idea as to how Panl interacts with Solr and the configuration options that are available.
Working through this chapter of the book will provide the thinking, design, and steps required to index the required dataset, configure the Panl server, and get it all up and running.
This chapter runs through the setup and configuration of Panl and Solr for a new and distinct dataset showing the path from
- Defining and setting up a Solr collection,
- Configuring the Panl server,
- Rendering the pages that are required for the user journey.
This dataset will be based on a bookstore[23] with the underlying data containing 3 million records - this dataset is not included with the release package (however a cut-down, cleaned version is included for testing). Running through this example will detail the decisions that are required and how the data was then utilised.
The process for pulling the components together is going to be the same regardless of the dataset that you are using.
- Understand the dataset
- Knowing what data is available,
- what cleanup process may be required,
- what data is missing, and
- whether data should be derived or included from a separate source.
- Configure the Solr index - Knowing how the underlying data will be indexed and surfaced to the Panl server. In general, one Solr collection, if set up correctly, will be able to drive multiple Panl configurations.
- Configure the Panl server - This applies to both the panl.properties file and <panl_collection_url>.panl.properties files. Remember: you may have multiple CaFUPs, so there may be multiple configuration files. Panl allows you to 'slice and dice' the underlying Solr search collections for specific use cases.
Finally, using the above information, and the functionality that each decision will provide:
- Determine any additional web pages to render - Apart from the default (or main) search page which is the first page to be configured.
This, almost certainly, will be an iterative process, with any of the steps requiring updates to the other steps and configuration. Having a good knowledge of the high-level requirements will enable you to quickly build up the configuration files for both the Solr and Panl servers, and then iterate over them. Additionally, this knowledge will help you make informed decisions about what to do with the dataset and the pages that this may lead to.
For example, when looking at the complete dataset, there are over 500,000 authors and there is a requirement to be able to have a page for each letter of the alphabet that would list the authors by their surname (thus limiting the number of facets). The dataset doesn't directly support this, so derived fields will need to be added (i.e. a field that is computed/derived from the dataset) which can then be indexed by the Solr server.
0. High Level Requirements
From a very high level perspective, the requirements for the bookstore are:
- The default keyword search should act upon the
- Title,
- Description,
- Author,
- Genre, and
- Series
- The user should be able to search upon specific Solr fields
- Title,
- Author,
- Book Description,
- Any combination of the above, or
- All of the above fields
- From the dataset, there will be hundreds of thousands of Authors, consequently, immediately displaying all Authors within a search facet would not be useful, however having facets based on the first letter of the Author's surname would be better.
- Have a unique link for every author being able to see if the author has any series, with links to books in the series.
- Users should be able to facet on specific fields that make sense from a search perspective.
|
|
Note: As the dataset is discovered, understood, and the way in which users will interact with the data, this may lead to other use-cases and requirements. (See the section on The Iterative Implementation Process for more details). |

1. Understanding the Dataset
Whether you are starting with an existing Solr managed schema, or you are looking to index a new dataset, understanding what the dataset contains is the MOST important part of the process. This will drive all other decisions - after all, without the correct data, you won't be able index it, search on it, facet upon it, or present it to the user.
The above may seem obvious, however, understanding the data, in conjunction with the desired pages that you want to render, will inform whether you can derive data from the underlying dataset, combine the dataset with other external datasets, or need to use a back-end datastore to generate pages with links.
In this example we will be looking at setting up a new dataset (and Solr collection) extracted from data containing just over 3 million records based on fiction books.
The original (and complete) dataset has duplicates, mis-spellings, missing information, and information that is just plain wrong. Before the indexing process, the data will need to be cleaned and any additional derived data generated. Overcoming the previous data problems, the cleaned dataset contains the following information, with some notes about we would want to search and facet the dataset
Data
- Author
- Search on the author, or authors (the book may have a collaboration of authors)
- Facet on the author, however with around 500,000 authors, we don't want to display all facets on the initial search page, so a derived field of the first letter of the Author's name would be good
- See a page that lists the author's works (in order of date of publication) with links to the series that are available
- See the author in the returned documents
- Title
- Search on the title, both collectively and as a specific field
- Will not be faceted, but will be displayed in the returned documents
- This data needs to be analysed to enable keyword searching
- Description
- Search on the description, both collectively and as a specific field
- Will not be faceted, but will be displayed in the returned documents
- This data needs to be analysed to enable keyword searching
- Book Image
- See the image of the book
- Will not be faceted, but will be displayed in the returned documents
- Buy URL
- See the link to the URL to buy the book
- Will not be faceted, but will be displayed in the returned documents
- Genre
- Search on the genre, collectively, but not be able to search on this specific field
- Be able to select multiple genres as a facet
- Number of Pages
- See the number of pages in a book in the returned document
- Will not be faceted, but will be displayed in the returned documents
- First published year
- See the first published year of the book
- Will be faceted, but as there are close to 100 years of books, we don't want to display every year on the initial search page, so a derived field of decade would be good.
- Language
- Select the language of the book
- Be able to select only a single language (even if the book is available in multiple languages)
- Paperback/Hardcover
- Select whether users want a hardcover, or paperback book
- Series
- Search on the series name, collectively, but not be able to search on this specific field
- Will be faceted, however as there will be many series of books, this should not appear with the initial results, but only when an author has been selected
- Price
- Select a price range for books
- Be able to sort by price range
- On Backorder
- Select whether to include books which are on backorder
- Will be faceted and use a BOOLEAN checkbox
- Speedy Delivery
- Select whether to only show books that are able to be delivered speedily
- Will be faceted and use a BOOLEAN checkbox
Derived Data
- ID - derived from the database primary key
- This is the required primary key for the Solr search server and the database primary key has been chosen for this purpose
- Author A-Z index - derived from the first character of the 'Author' surname
- Used to present a list of pages by the first letter of the author's surname
- Decade published - derived from 'Year published'
- Can be used to help narrow down the decade in which the book is published, i.e. the user should be able to select the decade first, and then be able to select the year within that decade
- Will be used as a facet
- Book type - derived from the 'Number of pages' - one of 'Flash Fiction', 'Short Story' 'Novelette', 'Novella', or 'Novel'
- Will be used as a facet
- Will not be returned with the search documents.
- Text - A general purpose field that will have its contents analysed and used for search queries
- Will be used for the search query
- Will have multiple other fields copied to it to be searched upon
- Will not be returned in the search documents
- Solr will generate this, rather than data being input.
- Text (Author) - A specific purpose field that will have its contents analysed and used for search queries
- Will be used for the specific search query
- Will have another fields 'Author' copied to it to be searched upon
- Will not be returned in the search documents
- Solr will generate this, rather than data being input
- This data type needs to be indexed to be searched upon
Now that the data types are known and how we are going to use them, let's determine how we are going to index them in the Solr search engine.
2. Configure the Solr Index
Whilst we are defining how the data will be indexed, we need to keep in mind the configuration of the Panl server as well. Looking at the data that you have indexed, or would like to index, the configuration of Panl is determined on the following items:
- Whether the Solr field should be configured in Panl as a facet, or just a field, and whether multiple values are available for the field, and
- Whether the Solr field will be analysed (through the Solr field type definition), and
- The data type of the Solr field, which will determine the configuration options that are available through the Panl server and whether this field can be used as a Specific Solr Field Search
REMEMBER
- Facets will allow you to filter the results.
- Fields will be returned with the search documents - you cannot filter (i.e. use these as facets) the results based on this field.
- Adding a Search property to either of the above will allow it to be a specific Solr search field, however if the underlying Solr field is not analysed, then this will not work.
Whether you choose a Solr field to be configured in Panl to be a Facet, or a Field, both
- Can be returned with the search documents
- Are able to be used for sorting options
The difference with Facets, is that in addition to the above
- Facets are able to be selected to filter the results and, depending on the data type, can be further configured for prefixes, suffixes, ranges, and value replacements
|
|
Note: If in doubt as to whether the Solr field will ever need to be configured as a Facet in Panl, err on the side of yes (i.e. set indexed="true"). Remember that the Panl configuration can present a Solr field as either a Facet or a Field, however if it is not set to indexed in the Solr configuration, it can only ever be a Field for Panl.
Be aware that indexing and storing of a field's data will use more storage space. |
Noting the following rules for Solr configuration:
- If we want to be able to search, sort, or facet on the data, then it must be indexed.
- If we want to see the results in the returned documents, then it must be stored
- If the dataset field can only hold a single value, then multivalued is No, otherwise it is set to Yes.
Using information above and the requirements for the dataset, the Solr field definitions for importing and indexing is as follows:
|
Solr Field Name |
Data Type |
Analysed |
Multi- |
Indexed |
Stored |
Specific Solr Search Field |
|
Author |
String |
No |
Yes |
Yes |
Yes |
No[24] |
|
Title |
Text |
Yes |
No |
Yes |
Yes |
Yes |
|
Description |
Text |
Yes |
No |
No |
Yes |
Yes |
|
Book Image |
String |
No |
No |
No |
Yes |
No |
|
Buy URL |
String |
No |
No |
No |
Yes |
No |
|
Genre |
String |
No |
Yes |
Yes |
Yes |
No |
|
Number of Pages |
Integer |
No |
No |
No |
Yes |
No |
|
First Published Year |
Integer |
No |
No |
Yes |
Yes |
No |
|
Language |
String |
No |
No |
Yes |
Yes |
No |
|
Paperback / Hardcover |
Boolean |
No |
No |
Yes |
Yes |
No |
|
Series |
String |
No |
No |
Yes |
Yes |
No |
|
Price |
Float |
No |
No |
Yes |
Yes |
No |
|
On Backorder |
Boolean |
No |
No |
Yes |
Yes |
No |
|
Speedy Delivery |
Boolean |
No |
No |
Yes |
Yes |
No |
|
Note: The following fields are derived from the dataset before being indexed by Solr |
||||||
|
ID |
Integer |
No |
No |
Yes |
Yes |
No |
|
Author A-Z index |
String |
No |
No |
Yes |
No |
No |
|
Decade First Published |
Integer |
No |
No |
Yes |
No |
No |
|
Book Length |
String |
No |
No |
Yes |
No |
No |
|
Text |
String |
Yes |
Yes |
Yes |
No |
No |
|
Text (Author) |
String |
Yes |
Yes |
Yes |
Yes |
Yes |
Note: To get a copy of the managed-schema.xml for your version of Solr, the configuration file can be found in the
SOLR_INSTALL_DIRECTORY/server/solr/configsets/_default/conf/
Copy this file to your project and edit it. The above table would lead to the following snippet of the Solr managed schema file with the Solr field names and values where set to true highlighted.
|
|
Remember: The way that the Solr managed schema is configured can span across multiple CaFUPs and that you do not need to configure Panl to include each facet or field for each of the pages that you want to render.
Configure the schema so that it will cover all requirements, and then let the Panl configuration define how the facets and results are returned.
If in doubt, you can always set up a separate Solr collection with a Panl configuration for a specific need or use case. |
|
|
IMPORTANT: Note the version of the schema below - it is set to 1.6, __NOT__ 1.7. |

|
01 02
03 04
05 06
07
08
09
10
11
12
13
14
15
16
17
18
19
20 21
22
23
24 25
26 27
28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<schema name="book-store" version="1.6"> <field name="_version_" type="plong" indexed="false" stored="false" ↩ docValues="true/>
<field name="id" type="string" stored="true" indexed="true" required="true" ↩ multiValued="false" />
<field name="author" type="string" indexed="true" stored="true" ↩ multiValued="true" /> <field name="title" type="text_general" indexed="true" stored="true" ↩ multiValued="false" /> <field name="description" type="text_general" indexed="true" stored="true" ↩ multiValued="false" /> <field name="book_image" type="string" indexed="false" stored="true" ↩ multiValued="false" /> <field name="buy_url" type="string" indexed="false" stored="true" ↩ multiValued="false" /> <field name="genre" type="string" indexed="true" stored="true" ↩ multiValued="true" /> <field name="num_pages" type="pint" indexed="false" stored="true" ↩ multiValued="false" /> <field name="first_published_year" type="pint" indexed="true" stored="true" ↩ multiValued="false" /> <field name="language" type="string" indexed="true" stored="true" ↩ multiValued="false" /> <field name="is_paperback" type="boolean" indexed="true" stored="true" ↩ multiValued="false" /> <field name="series" type="string" indexed="true" stored="true" ↩ multiValued="false" /> <field name="price" type="pfloat" indexed="true" stored="true" ↩ multiValued="false" /> <field name="on_backorder" type="boolean" indexed="true" stored="true" ↩ multiValued="false" /> <field name="speedy_delivery" type="boolean" indexed="true" stored="true" ↩ multiValued="false" />
<field name="a_to_z_index" type="string" indexed="true" stored="false" ↩ multiValued="false" /> <field name="decade_published" type="pint" indexed="true" stored="false" ↩ multiValued="false" /> <field name="book_length" type="string" indexed="true" stored="false" ↩ multiValued="false" />
<field name="text" type="text_general" indexed="true" stored="false" ↩ multiValued="true" />
<field name="text_author" type="text_general" indexed="true" stored="true" ↩ multiValued="true" />
<uniqueKey>id</uniqueKey>
<copyField source="author" dest="text" /> <copyField source="title" dest="text" /> <copyField source="description" dest="text" /> <copyField source="genre" dest="text" /> <copyField source="series" dest="text" />
<copyField source="author" dest="text_author" />
...
</schema> |
Working through the schema:
Line 1:
This defines the schema name (book-store) which maps to the Solr collection name and will be used by Panl for the CaFUPs. WARNING: if the schema name starts with the string panl- then the Panl server will fail to start as this is reserved by the Panl server.[25]
Line 2:
The _version_ field is required by a Solr Cloud deployment - this is an internal field, generated automatically by Solr and is used by the partial update procedure, the update log process. You may not need to have this field, however it is mandatory for a Solr Cloud instance. NOTE: In version 10 of Solr, cloud mode will be enabled by default.
Line 4:
The id field for uniquely identifying a Solr document within the collection, this makes it easy to update a specific document and enable highlighting.
Lines 6 - 19:
The fields that come directly from the bookstore dataset, note the values of the XML element for the attributes multivalued, indexed, and stored
Lines 21-23:
The fields that are derived from the data.
Line 25:
This is an analysed field that is used as a storage area for every other field that needs to be searched on - see lines 31-35 for the fields that are copied to this field.
Line 27:
This is an analysed field that is used as a storage area for the Author - this is done as the Author is both a Specific Search Field and a Facet.
Line 29:
This element tells Solr what the unique key is for this collection
Lines 31-35:
This copies the values from the required fields so that they can be analysed by Solr and searched upon with a keyword or keywords.
Line 37:
This copies the value from the non-analysed author field to the analysed text_author field so that the text_author field may be used for a Specific Solr Search Field.
Line 39:
For clarity and space, the Solr field definitions and additional XML elements were not included and replaced by ellipses.
Line 41:
The end of the Solr schema definition
|
|
IMPORTANT: When defining the managed schema for a Solr collection, you need to consider __ALL__ of the use cases of the data and whether each field is going to be indexed and/or stored.
You can then configure the Panl server through the CaFUPs to facet and return just the individual facets and fields that you want. |
3. Configure the Panl Server
Now that we understand the dataset and how the Solr search server is going to index the data, we can extend the Solr field definitions for the initial Panl configuration.
|
|
Notes: The following configuration is for the default search page, alternate configurations will be defined for further search page implementations. |
|
Solr Field Name |
Data Type |
Facet, or Field |
Facet Type |
Sortable |
Additional Information |
|
Note: The following field is required for Solr Cloud deployments and MUST NOT be explicitly set when indexing the data - Solr will automatically set this value. |
|||||
|
_version_ |
Long |
N/A |
N/A |
N/A |
Ignored by Panl generator |
|
Note: The following fields are defined for the Bookstore dataset |
|||||
|
ID |
String |
Facet |
REGULAR |
No |
Unique Key |
|
Author |
String |
Facet |
REGULAR |
No |
Hierarchical, Prefix/Suffix |
|
Title |
Text |
Field |
N/A |
No |
Specific search |
|
Description |
Text |
Field |
N/A |
No |
Specific search |
|
Book Image |
String |
Field |
N/A |
No |
|
|
Buy URL |
String |
Field |
N/A |
No |
|
|
Genre |
String |
Facet |
OR |
No |
Prefix/Suffix |
|
Number of Pages |
Integer |
Field |
N/A |
No |
|
|
First Published Year |
Integer |
Facet |
REGULAR |
Yes |
Hierarchical, Prefix/Suffix |
|
Language |
String |
Facet |
REGULAR |
No |
|
|
Paperback / Hardcover |
Boolean |
Facet |
BOOLEAN |
No |
Value replacement |
|
Series |
String |
Facet |
REGULAR |
No |
Hierarchical |
|
Price |
Float |
Facet |
RANGE |
Yes |
|
|
On Backorder |
Boolean |
Facet |
BOOLEAN |
No |
Checkbox |
|
Speedy Delivery |
Boolean |
Facet |
BOOLEAN |
No |
Checkbox |
|
Note: The following fields are derived from the dataset before being indexed by Solr |
|||||
|
Author A-Z index |
String |
Facet |
REGULAR |
Yes |
Index Facet Sort |
|
Decade First Published |
Integer |
Facet |
REGULAR |
No |
|
|
Book length |
String |
Facet |
REGULAR |
No |
|
|
Text |
Text |
Search |
N/A |
No |
Default search field |
|
Text (Author) |
Text |
Search |
N/A |
No |
Specific search |
The above can be considered the default search page configuration, there will be other <panl_collection_url>.panl.properties files defined.
Where the Additional Information column has a comment of 'Specific search', these fields are used for the Specific Solr Search Field keyword searching.
Configuring A Facet AND A Specific Solr Search Field
Whilst this is possible, the results may not be in the desired format. In the Bookstore example, if the Author field has been designated as a Facet AND a Specific Solr Search Field. Without additional configuration, the Facet will return the tokenised values, rather than the stored values, e.g. the URL:
http://localhost:8181/panl-results-viewer/book-store/default/C/A/
Which is returning all Authors that begin with the letter C. If the Author field is configured to be a Facet AND a specific search field, the Facet will return the following values:
|
|

To get around this, the Author field is set to be just indexed and is not of a type that is analysed. Then, a second field, text_author is created (indexed, stored, and analysed) with the contents of the author field copied into it. This can then be used as a Specific Solr Search FIeld without impacting the author.
The Default Search Page Configuration
To generate the default search page configuration the in-built Panl generator utility is the quickest way to produce the files.
For more information on the available options, see the section for the command line options for the Panl Generator in the appendices.
|
|
IMPORTANT: Be aware that every time that you use the Panl generator, there is a chance that the generated files will change their LPSE codes. This will happen if the Panl generator has a LPSE code that cannot be assigned from the first character of the Solr field name (either upper or lowercase) as they are already both in use and will then choose a random one. |
*NIX commands
|
Command(s) |
|
cd PANL_INSTALL_DIRECTORY
bin/panl generate ↩ |
Windows commands
|
Command(s) |
|
cd PANL_INSTALL_DIRECTORY
bin\panl.bat generate ↩ |
You will be asked to enter the default LPSE codes for the Panl parameters, just press Enter/Return to accept the defaults.
|
|
IMPORTANT: If you do not accept the default values for the Panl parameters, then the examples in this book most probably won't work, however you may choose whichever Panl parameter value for your implementation that you wish. |
This will generate two files in the src/dist/sample/panl/book-store/ directory named panl.properties and book-store.panl.properties, the text of which is not included in this book - however the complete files can be seen in the GitHub repository
https://github.com/synapticloop/panl/tree/main/src/dist/sample/panl/book-store
Note: There is an additional file in the directory which configures highlighting for the Bookstore collection.
The Generated panl.properties File
The Panl generator utility will output the file to the path passed in through the -properties command line option (or the current directory if this option is not passed in).
For all Bookstore URL path parts, the panl.properties file will be the same. Below (for clarity) all comments have been stripped from the file. Note the last line panl.collection.book-store=book-store.panl.properties was automatically added to the file.
|
01 02 03 04 05 06 07 |
solrj.client=CloudSolrClient solr.search.server.url=http://localhost:8983/solr,http://localhost:7574/solr panl.results.testing.urls=true panl.status.404.verbose=true panl.status.500.verbose=true panl.decimal.point=true panl.collection.book-store=book-store.panl.properties |
|
|
Note: The above is configured for testing purposes, with verbose error messaging and testing URLs live (Lines 3 to 5). |
The Generated <panl_collection_url>.panl.properties File
The second file that the Panl generator utility will write is the <panl_collection_url>.panl.properties file. This file has three major parts (in order):
- The general properties configuration,
- The generated fields and facets configuration, and
- The Panl LPSE order, FieldSets, and sorting
General Properties Configuration
Skipping over the defaults values for the panl.param.* properties (and no prefixes or suffixes were added to either the panl.param.page or panl.param.numrows properties) the following properties were changed:
solr.numrows.default=20
solr.numrows.maximum=20
Both of these values were changed from the default value of 10 as 20 results seems to be a good starting point for such a large collection
solr.highlight=false
No changes for the default value of 'false', no highlighting will be required on the Bookstore collection. Note: there is a separate Panl collections file that has an implementation for highlighting.
panl.lpse.ignore=id
We still want to be able to search on this field and be able to pull out the results but we don't want to return the id field as a facet. The general use is with a canonical URL - e.g.
/Michael Connelly Harry Bosh Series The Black Echo/1/zi/
And use the id Solr field (LPSE code 'i') as the lookup key with the value 1, the rest of the URL path part will be ignored.
panl.sort.fields=price,a_to_z_index,first_published_year
These are the fields that are going to be able to be sortable - remember that relevancy is always the default sort order if no other sort order is selected. The order of the value of this property is the sorting order that Panl will return in the JSON response object.
The Generated Fields and Facets Configurations
Comments providing information about the settings and any non-configured properties have been removed from the examples below.
Solr Field 'id'
|
01
02 03 04 |
# <field "indexed"="true" "stored"="true" "name"="id" "type"="string" ↩ panl.facet.i=id panl.name.i=Id panl.type.i=solr.StrField |
This facet will be left as it is for the moment, but this will be ignored by the Panl server as the property panl.lpse.ignore=id has this LPSE code.
You can still return this as a field in the Panl results, so that if you need the unique id of the book for additional functionality (e.g. adding to a cart, linking to a separate page, looking up further details). See the panl.results.fields.* properties.
Solr Field 'author'
|
01
02 03 04 05 06 07 |
# <field name="author" type="string" indexed="true" stored="true" ↩ panl.facet.a=author panl.name.a=Author panl.type.a=solr.StrField panl.multivalue.a=true panl.prefix.a=Author panl.when.a=q,A |
A prefix has been added on line 6 of 'Author ' (note the ending whitespace which is not clear from the above text snippet).
There are too many authors to have this as a facet, and they will be ordered by the number of books that have been published, so this facet is configured to only appear if a search query is set, or if the first letter of the surname is selected. Consequently line 8 has been un-commented so that the panl.when.a property has a value. This facet will only appear if the search query (LPSE code 'q') or the a_to_z_index facet (LPSE code 'A') has been selected.
In the below image, a keyword search of 'Mary' was entered and three authors were returned:
Image: The Author facet display for the keyword search 'Mary'

Solr field 'title'
|
01
02 03 04 05 |
# <field "indexed"="true" "stored"="true" "name"="title" "type"="text_general" ↩ "multiValued"="false" /> panl.field.t=title panl.search.t=title panl.name.t=Title panl.type.t=solr.TextField |
The generator has configured this Solr field as a Panl facet as it is both indexed and stored in Solr - this has been changed to a field, rather than a facet. This field can then be returned with the results.
Additionally this field has been configured to be a specific field search with the panl.search.t=title property.
Solr field 'description'
|
01
02 03 04 |
# <field "indexed"="true" "stored"="true" "name"="description" ↩ "type"="text_general" "multiValued"="false" /> panl.field.d=description panl.search.d=description panl.name.d=Description panl.type.d=solr.TextField |
The generator has configured this Solr field as a Panl facet as it is both indexed and stored in Solr - this has been changed to a field, rather than a facet. This field can then be returned with the results.
Additionally this field has been configured to be a specific field search with the panl.search.d=description property.
Solr field 'book_image'
No configuration changes made, the Panl generator automatically configured this as a field as the Solr field is not indexed. This field can then be returned with the results.
|
01
02 03 04 |
# <field "indexed"="false" "stored"="true" "name"="book_image" "type"="string" ↩ panl.field.b=book_image panl.name.b=Book Image panl.type.b=solr.StrField |
Solr field 'buy_url'
No configuration changes made, the Panl generator automatically configured this as a field as the Solr field is not indexed. This field can then be returned with the results.
|
01
02 03 04 |
# <field "indexed"="false" "stored"="true" "name"="buy_url" "type"="string" ↩ panl.field.B=buy_url panl.name.B=Buy Url panl.type.B=solr.StrField |
Solr field 'genre'
|
01
02 03 04 05 06 07 08 |
# <field "indexed"="true" "stored"="true" "name"="genre" "type"="string" ↩ "multiValued"="true" /> panl.facet.g=genre panl.or.facet.g=true panl.name.g=Genre panl.type.g=solr.StrField panl.multivalue.g=true panl.or.separator.g=, panl.prefix.g=Genres: |
This will be configured to be an OR facet as it is configured with the property panl.or.facet.g=true, meaning that end users can select one or more of the facet values.
Additionally, to make the URL nicer a prefix of 'Genres:' is added, with an OR separator of a single comma ','.
Note: This is already a multivalued Solr field, however using this as an OR facet means that you can select books which are 'Sci-Fi' OR 'Horror', rather than a book that is 'Sci-Fi' AND 'Horror'.
Image: The genres facet
As this is set as an OR Separator facet, as Genres are added, the separator is used between values:
http://localhost:8181/panl-results-viewer/book-store/default/Genres:Thriller/g/
http://localhost:8181/panl-results-viewer/book-store/default/Genres:Thriller,Detective/g/
Solr field 'num_pages'
No configuration changes made
|
01
02 03 04 |
# <field "indexed"="false" "stored"="true" "name"="num_pages" "type"="pint" ↩ "multiValued"="false" /> panl.field.N=num_pages panl.name.N=Num Pages panl.type.N=solr.IntPointField |
Solr field 'first_published_year'
|
01
02 03 04 05 06 |
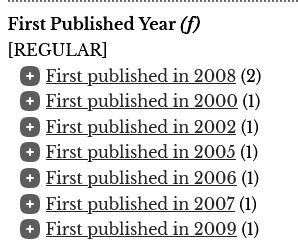
# <field "indexed"="true" "stored"="true" "name"="first_published_year" ↩ "type"="pint" "multiValued"="false" /> panl.facet.f=first_published_year panl.name.f=First Published Year panl.type.f=solr.IntPointField panl.prefix.f=First published in panl.when.f=D |
Add in a prefix of 'First published in ' - Line 5 - and this will only appear when the decade_published facet has been selected (LPSE code 'D') - Line 6.
When a decade is selected, the 'First Published Year' facet is then displayed, for example, the URL
http://localhost:8181/panl-results-viewer/book-store/default/
Will not display the facet, however, once a Decade facet is selected:
http://localhost:8181/panl-results-viewer/book-store/default/2000/D/
The facet will be displayed:
Image: The First Published Year facet with the selections for the decade 2000 and the prefix of 'First published in'
Solr field 'language'
No configuration changes made
|
01
02 03 04 |
# <field "indexed"="true" "stored"="true" "name"="language" "type"="string" ↩ panl.facet.l=language panl.name.l=Language panl.type.l=solr.StrField |
Because the indexed data has only one language - "English" this facet will not appear - this is due to the configuration property panl.include.single.facets=false, which will not show facets with only a single value. This is also affected by the panl.include.same.number.facets=false property as facets will not be returned if the count is the same as number of results (i.e. by selecting the facet, this will not reduce/filter the number of results).
If they were both set to 'true', then the facet would be displayed.
Solr field 'is_paperback'
|
01
02 03 04 05 06 |
# <field "indexed"="true" "stored"="true" "name"="is_paperback" "type"="boolean" ↩ panl.facet.I=is_paperback panl.name.I=Book Format panl.type.I=solr.BoolField panl.bool.I.true=Paperback panl.bool.I.false=Hardcover |
The display name has been changed to be 'Book Format' (Line 3) and a Boolean value replacement for both the true and false values (Lines 5 and 6).
Another way that this could have been indexed by Solr was to derive the data and store the book format as a string - i.e. type="string" with the values 'Paperback' and 'Hardcover', however keeping this as a boolean value with value replacements means that additional CaFUPs could be configured with different values for true and false if additional URLs were needed to be generated.
Image: The Book Format facet with the BOOLEAN value replacement
Solr field 'series'
|
01
02 03 04 05 |
# <field "indexed"="true" "stored"="true" "name"="series" "type"="string" ↩ panl.facet.S=series panl.name.S=Series panl.type.S=solr.StrField panl.when.S=a |
This facet will only be passed through if an author facet (LPSE code 'a') has been selected (Line 5).
For the Series facet to be displayed, the Author facet would have to be selected first, however, for the Author facet to be displayed, either the Authors A-Z (LPSE code 'A') must be selected first.
An example of the URL that will enable the series facet to be displayed:
http://localhost:8181/panl-results-viewer/book-store/default/Author%20Michael%20Connelly/C/aA/
Image: The Series facet that will only be displayed if the 'a' LPSE code is already selected.

Solr field 'price'
|
01
02 03 04 05 06 07 08 09 10 11 12 |
# <field "indexed"="true" "stored"="true" "name"="price" "type"="pfloat" ↩ "multiValued"="false" /> panl.facet.P=price panl.name.P=Price panl.type.P=solr.FloatPointField panl.range.facet.P=true panl.range.min.P=5 panl.range.max.P=100 panl.range.prefix.P=From panl.range.infix.P=\ to panl.range.suffix.P=\ dollars panl.range.min.wildcard.P=true panl.range.max.wildcard.P=true |
This facet is a RANGE facet (configured with the panl.range.facet.P=true property) - Lines 5 to 12. As an example, the configuration will generate the URL path part.
/From 5 to 100 dollars/P/
Additionally, with the wildcard properties set (i.e. panl.range.min.wildcard.P=true and panl.range.max.wildcard.P=true), it will generate a Solr query when the minimum or maximum values are passed through to use less than or greater than, respectively. I.e. if the URL path part was used, as they are both a minimum and maximum value, the query would prices between 5 or below and 100 and greater.
For a URL path part of
/From 20 to 100 dollars/P/
It would return books greater than 20 (even if they are greater than 100)
For the URL path part of
/From 45 to 50 dollars/P/
It will only return values between 45 and 50 (inclusive)
Image: The price RANGE Facet

Note the actual dynamic range is 11 to 35 - i.e. for this search, the books fall between 11 and 35 dollars.
Solr field 'on_backorder'
|
01
02 03 04 05 06 07 |
# <field "indexed"="true" "stored"="true" "name"="on_backorder" "type"="boolean" ↩ "multiValued"="false" /> panl.facet.O=on_backorder panl.name.O=On Backorder panl.type.O=solr.BoolField panl.bool.O.true=On Backorder panl.bool.O.false=In Stock panl.bool.checkbox.O=false |
This is a BOOLEAN Facet which is to be presented as a checkbox. When the checkbox is selected, then it will select all books which have this value set to 'false'.
Image: The BOOLEAN Checkbox facet

On selecting the "Exclude 'On Backorder'" checkbox, any books that are on backorder will be removed from the results. When unselected, then all books, regardless of the value of this field will be selected.
A side-effect of this is that you CANNOT select books which are on backorder only with this implementation. This is not to say that you couldn't have another CaFUP that would allow this functionality.
Solr field 'speedy_delivery'
|
01
02 03 04 05 06 07 |
# <field "indexed"="true" "stored"="true" "name"="speedy_delivery" ↩ panl.facet.V=speedy_delivery panl.name.V=Speedy Delivery panl.type.V=solr.BoolField panl.bool.V.true=Speedy Delivery panl.bool.V.false=Regular Delivery panl.bool.checkbox.V=true |
This is a BOOLEAN Facet which is to be presented as a checkbox. When the checkbox is selected, then it will select all books which have this value set to 'true'.
Image: The BOOLEAN Checkbox facet

On selecting the "Only include 'Speedy Delivery'" checkbox, any books that have a speedy delivery option will be included in the results. When unselected, then all books, regardless of the value of this field will be selected.
A side-effect of this is that you CANNOT select books which do not have speedy delivery in this implementation. This is not to say that you couldn't have another CaFUP that would allow this functionality.
Solr field 'a-to-z-index'
|
01
02 03 04 05 |
# <field "indexed"="true" "stored"="false" "name"="a_to_z_index" "type"="string" ↩ "multiValued"="false" /> panl.facet.A=a_to_z_index panl.name.A=Authors (A-Z) panl.type.A=solr.StrField panl.facetsort.A=index |
The Panl name was updated to 'Authors (A-Z)' and the sorting of the facet was set to index so that the facet values were ordered in alphabetical order.
Image: The Authors (A-Z) facet
Solr field 'decade_published'
No configuration changes made
|
01
02 03 04 |
# <field "indexed"="true" "stored"="false" "name"="decade_published" ↩ "type"="pint" "multiValued"="false" /> panl.facet.D=decade_published panl.name.D=Decade Published panl.type.D=solr.IntPointField |
Image: The Decades facet

Note that the Decades are not in numerical order, they are ordered by the count of the values, this is the default behaviour of the Panl server. You may wish to change this and have them ordered by the decade, in which case add a property panl.facetsort.D=index.
Solr field 'book_length'
No configuration changes made
|
01
02 03 04 |
# <field "indexed"="true" "stored"="false" "name"="book_length" "type"="string" ↩ "multiValued"="false" /> panl.facet.L=book_length panl.name.L=Book Length panl.type.L=solr.StrField |
Solr field 'text'
|
01
02 03 04 |
# <field "indexed"="true" "stored"="false" "name"="text" "type"="text_general" ↩ "multiValued"="true" /> #panl.facet.v=text #panl.name.v=Text #panl.type.v=solr.TextField |
This is an internal Solr field that is used as a multi valued text field to store all fields that need to be searched against. As such, it is not going to be used as a facet, or a field, so the entire entry has been commented out.
|
|
IMPORTANT: Ensure that you remove the 'text' field from all Panl configured FieldSets and LPSE orders, as the Panl server will error on startup if it finds a field that it is not defined - see the following properties:
|
Solr field 'text_author'
|
01
02 03 04 05 06 |
# <field "indexed"="true" "stored"="false" "name"="text_author" ↩ "type"="text_general" "multiValued"="true" /> panl.field.T=text_author panl.search.T=text_author panl.name.T=Author panl.type.T=solr.TextField panl.multivalue.T=true |
This is a Solr field that is used as a multi-valued text field to store the Author field (via the copyField XML directive so that it is enabled for the Specific Solr Field Search (Line 3).
For Solr field's 'text_author', 'description' and 'title'
These are configured to be the Specific Solr Search Fields and must be added to the panl.search.fields property.
|
01 02 03 |
panl.search.fields=title,\ text_author^4,\ description |
In the above configuration, the three fields are set up to be presented as Specific Solr Search fields. You will notice that text_author has a Solr query boost of 4 - as the definition of the field is the name and the boost value text_author^4 - note the caret character '^4' and the boost value of '4'.
|
|
IMPORTANT: Even though the 'text_author', 'title', and 'description' fields have been configured to be Specific Solr Search Fields, they will not be enabled unless the Solr field name is also included in the panl.search.fields property.
The reasoning behind this is twofold:
(As a side note - it also makes it easier to copy and paste various files when creating new Panl CaFUPS). |
Final Configuration Items
The final part of the Panl configuration is to define the
- LPSE order,
- LPSE ignore fields,
- FieldSets,
- Sorting the results/documents on available fields/facets, and
- Specific Solr fields to be searched on
LPSE Ignore
This property configures Panl to ignore certain LPSE codes in the returned JSON response. The reason to do this is that you may wish to suppress fields being returned. The major use case is when you wish to use the id field as the facet with a passthrough parameter.
The Panl LPSE Order
The LPSE order is the order of the codes for both:
- The generated Panl URL, and
- The order of the available and active facets returned in the JSON response (be aware that this is just for the order of the facets within each JSON key and some facets are in separate sections - for example RANGE and DATE Range facets).
- If you wish to have a separate order for the returned facets - see the panl.lpse.facetorder.
So the LPSE order becomes
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
panl.lpse.order=z,\ id,\ author,\ title,\ description,\ book_image,\ buy_url,\ genre,\ num_pages,\ first_published_year,\ language,\ is_paperback,\ series,\ price,\ on_backorder,\ speedy_delivery,\ a_to_z_index,\ decade_published,\ book_length,\ q,\ p,\ n,\ s,\ o |
|
|
Notes: The panl.lpse.order can also use the defined LPSE codes - using the Solr Field Names makes it easier to understand what the LPSE order is. |
The Panl FieldSets
There are always going to be at least two FieldSets defined for any Panl collection, namely:
- default - this is ALWAYS available, and if not set then it will return ALL fields in the Solr collection, whether you have defined them in the Panl configuration file or not. The recommendation is to either ignore this in your implementation, or edit this FieldSet to your purposes, as has been done below.
- empty - this is ALWAYS available, and if it appears in the properties file, a warning will be printed and it will be ignored. This will return no fields for the document (i.e. no documents at all).
Here, the only configured FieldSets is going to be the default, with no other FieldSets defined. I.e. the panl.results.fields.firstfive property has been removed.
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 |
panl.results.fields.default=id,\ author,\ title,\ description,\ book_image,\ buy_url,\ genre,\ num_pages,\ first_published_year,\ language,\ is_paperback,\ series,\ price,\ on_backorder,\ speedy_delivery,\ a_to_z_index,\ decade_published,\ book_length,\ text |
Lines 16 to 29 have been removed. The id field (Line 1) was kept in as it may be useful to link to the database for other purposes. The final property looks thusly:
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 |
panl.results.fields.default=id,\ author,\ title,\ description,\ book_image,\ buy_url,\ genre,\ num_pages,\ first_published_year,\ language,\ is_paperback,\ series,\ price,\ on_backorder,\ speedy_delivery |
The Panl Sort Fields
To define the sort fields, use the panl.sort.fields property with a list of comma separated values. Each of the sort fields must match the Solr field name, NOT the Panl LPSE code as these are passed directly through to the Solr server.
panl.sort.fields=price,a_to_z_index,first_published_year
|
|
Note: There is only one sorting fields property for the file and spans across all FieldSets defined in this file. You may add as many sorting fields as you would like, however you do not need to make the options available to the end user. |
The Specific Solr Search Field Configuration
To define the specific search fields, use the panl.search.fields property with a list of comma separated values. Each of the sort fields must match the Solr field name, NOT the Panl LPSE code as these are passed directly through to the Solr server.
panl.search.fields=title,\
text_author^4,\
description
Image: The Specific Solr Search Fields that are defined

Note that the ^4 in the text_author^4 is the query boost that is applied to the field if that specific field is selected to be searched upon.
The Difference Between The Default Search And The Specific Search
For a simple keyword search of 'fiction', the default search - which will search on all fields that are copied to the 'text' field - these are author, title, description, genre, series.
This keyword search will return all documents that have 'fiction' in any of the fields, including the 'genre' field.
http://localhost:8181/panl-results-viewer/book-store/default/fiction/q/
When using all fields in the specific search these are text_author, title, description, then the specific field search will return fewer results.
http://localhost:8181/panl-results-viewer/book-store/default/fiction/q(tTd)/
Whilst this may seem obvious, just be aware that the default search and the specific search may be using different fields to search on.
How Boosting Works
For a simple keyword search of 'Mary', the default search - which will search on all fields that are copied to the 'text' field - these are author, title, description, genre, series.
http://localhost:8181/panl-results-viewer/book-store/default/Mary/q/
Will return the following results
- P. L. Travers // "Mary Poppins Comes Back"
The series name, title, and description contain the keyword - P. L. Travers // "Mary Poppins"
The series name, title, and description contain the keyword - Mary Kennedy // "Mary's Angel"
The author, title, and description contain the keyword - Andy Weir // "Project Hail Mary"
The title and description contains the keyword - Frances Hodgson Burnett // "The Secret Garden"
The description contains the keyword in the snippet "... tells the enchanting story of Mary Lennox, a spoiled and lonely girl ..." - Mary Wollstonecraft Shelley // "Frankenstein"
The author and description contains the keyword
For Specific Solr Field Searches, the only checkboxes that are available are text_author, title, and description, If the user selects all checkboxes (without any query boosting configured, the search is only done on those checkboxes and the fields genre, series are ignored).
If query boosting is enabled (in the Bookstore example, the author field is boosted with text_author^4
http://localhost:8181/panl-results-viewer/book-store/default/Mary/q(tTd)/
which will return the results in the following order:
- Mary Kennedy // "Mary's Angel"[26]
The author, title, and description contain the keyword - Mary Wollstonecraft Shelley // "Frankenstein"
The author and description contains the keyword - P. L. Travers // "Mary Poppins Comes Back"
The description and the title contain the keyword - P. L. Travers // "Mary Poppins"
The description and the title contain the keyword - Andy Weir // "Project Hail Mary"
The description and title contains the keyword - Frances Hodgson Burnett // "The Secret Garden"
The description contains the keyword in the snippet "... tells the enchanting story of Mary Lennox, a spoiled and lonely girl ..."
Note that Mary Wollstonecraft Shelley // "Frankenstein" now is the first result because the Author field contains the keyword and is boosted.
Highlighting
An additional Panl collection properties file was included in the sample directory book-store-hl.panl.properties which includes highlighting turned on - i.e. solr.highlight=true - this is the only difference between the files. The implementation through the in-built Panl Results Viewer is basic at best.
Note: This will only work for Specific Solr Search Field queries, not the default one.
Example without highlighting:
http://localhost:8181/panl-results-viewer/book-store/default/fiction/q(tTd)/
Image: A search for 'fiction' without highlighting

And with highlighting:
http://localhost:8181/panl-results-viewer/book-store-hl/default/fiction/q(tTd)/
Image: A search for 'fiction' with highlighting

|
|
IMPORTANT: Read the section on highlighting to gain a better understanding of the requirements. It is a good idea to include the XML attribute termVectors="true" on fields that you want to be highlighted. |
Loading the Configuration and Indexing the Dataset
As a quick reminder, for the Solr server:
- The configuration needs to be uploaded to the Solr server
- The data must be indexed
Windows Commands
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
bin\solr.cmd create -c book-store -d ↩
bin\solr.cmd post -c simple-date ↩ |
*NIX Commands
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
bin/solr create -c book-store -d ↩
bin/solr post -c simple-date ↩ |
Testing the Configuration
At this point (assuming that the data has been correctly added and indexed to the Solr Search server) you will be able to start the Panl server and view your single CaFUP on the Panl Results Viewer - http://localhost:8181/panl-results-viewer/book-store/default/.
As a reminder of the commands to start up the Panl server:
Windows Commands
|
Command(s) |
|
cd PANL_INSTALL_DIRECTORY
bin\panl.bat -properties ↩ |
*NIX Commands
|
Command(s) |
|
cd PANL_INSTALL_DIRECTORY
bin/panl -properties ↩ |
Configuration Change Summary
|
Panl Field Name |
LPSE code |
Changes |
|||
|
id |
i |
Added to ignored facet by setting (NOTE: that the Solr field name is below, however, the LPSE code could also be used) panl.lpse.ignore=id |
|||
|
Author |
a |
Added hierarchy by setting panl.when.a=q,A Added prefix by setting panl.prefix.a=Author . |
|||
|
Title |
t |
Changed from a facet to a field - i.e. panl.facet.t=title to panl.field.t=title Remove field from panl.lpse.order Added specific field search panl.search.t=title . |
|||
|
Description |
d |
Changed from a facet to a field - i.e. panl.facet.d=description to panl.field.d=description Remove field from panl.lpse.order Added specific field search panl.search.d=description . |
|||
|
Book Image |
b |
No changes to Panl field/facet configuration |
|||
|
Buy URL |
B |
No changes to Panl field/facet configuration |
|||
|
Genre |
g |
Made this an OR facet with a separator and a prefix of 'Genres:' by setting panl.or.facet.g=true panl.prefix.g=Genres: panl.or.separator.g=, |
|||
|
Number of Pages |
N |
No changes to Panl field/facet configuration |
|||
|
First Published Year |
f |
Added a prefix by setting panl.prefix.f=First published in . Added to sort fields by adding to the property panl.sort.fields |
|||
|
Language |
l |
No changes to Panl field/facet configuration |
|||
|
Paperback / Hardcover |
I |
Changed the Panl name by setting panl.name.I=Book Format Added BOOLEAN value replacement values by setting panl.bool.I.true=Paperback panl.bool.I.false=Hardcover |
|||
|
Series |
S |
Added hierarchy by setting panl.when.S=a |
|||
|
Price |
P |
Made this a RANGE facet with value replacement by setting the following panl.range.facet.P=true panl.range.min.P=5 panl.range.max.P=100 panl.range.prefix.P=From . panl.range.infix.P=\ to . panl.range.suffix.P=\ dollars panl.range.min.wildcard.P=true panl.range.max.wildcard.P=true Added to sort fields by adding to the property panl.sort.fields |
|||
|
On Backorder |
O |
This is a BOOLEAN checkbox facet, with true/false value replacement. panl.bool.O.true=On Backorder panl.bool.O.false=In Stock panl.bool.checkbox.O=false |
|||
|
Speedy Delivery |
V |
This is a BOOLEAN checkbox facet. panl.bool.checkbox.V=true |
|||
|
Note: The following fields are derived from the dataset before being indexed by Solr |
|||||
|
|
|
|
|||
|
Author A-Z index |
A |
Change the Panl field name by setting panl.name.A=Authors (A-Z) Removed field from Panl.results.fields.default Added to sort fields by adding to the property panl.sort.fields Added sorting of the facet values by index, rather than count panl.facetsort.A=index |
|||
|
Decade First Published |
D |
Removed field from panl.results.fields.default |
|||
|
Book length |
L |
Removed field from panl.results.fields.default |
|||
|
Text |
v |
Commented out all properties for this field Remove field from panl.lpse.order Removed field from panl.results.fields.default |
|||
|
Text (Author) |
T |
Changed name of field to be panl.name.T=Author Remove field from panl.lpse.order Added specific field search panl.search.T=text_author . |
|||
4. Determine the Web Pages to Render
In addition to the default (i.e. main) search page with its functionality, additional page requirements are as follows.
- SEO friendly URLs that list of all books published by author (in order of publication) along with the ability to facet by any series that the author has written.
- SEO friendly URLs that lists all book series for Authors (in order of publication) that exist
- A list of all Authors with their associated books and their series
Author and Author Series
Both of these pages can be generated with a single Panl configuration (included as the dist/sample/panl/book-store/author-alphabetical.panl.properties file) For each of the links to the authors, a link was generated in the format of /Author <author_name>/a/ and then the Panl server was left to do its work.
|
|
Tips: The majority of these pages could also be directly generated through a database query, however you would also need to implement sorting, pagination, and any additional faceting as well, all of which Panl has built-in and ready to use. |
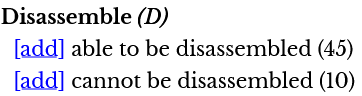
Author Listing
The indexing of the author listing page - i.e. a complete list of all authors within the dataset could not sufficiently be satisfied by the current dataset, so a new dataset was created and indexed by Solr (not included in the release package). The required pages were then produced and functionality added by passing it through the Panl server to utilise the searching, sorting, pagination, and hierarchical facets.
A single Panl solution may not fit all use cases so you may need to look at additional datasets, or simply by using pages generated from a database.
The Iterative Implementation Process[27]
When testing the configurations, the original implementation didn't quite make sense, so
- The way the dataset was indexed by the Solr collection didn't suit all of the needs, so a separate collection was created to hold only an individual author with a multifield list of titles attached to it.
- Searching a book by decade didn't really make sense (or even having the hierarchical facet for first_published_in). They were removed as facets and made to be fields. The data was left in the Solr collection index, as they may be of use later.
- The site that was generated was a joining of the web application server, the database, and then the Panl configuration. Some pages were generated by the database and served up by the web application which were then linked to the Panl implementation.
- Any Solr fields that are of type float, when returned with the documents there may be storage errors, for example, each of the books are priced as a float as 19.99, when returned with the document, it comes back as 19.989999771118164 - which rounds to 19.99. Instead another field was derived to have it as an integer for price in cents, then on the front end, just formatted it to the correct decimal place.
The changes made and implementation details have not been provided in the included sample dataset.
The Panl server runs purely on configuration, so any changes that are made to either of the configurations will be utilised at runtime. Provided that the Solr collection is set up to allow the broadest array of functionality, this becomes a very short iterative process.
~ ~ ~ * ~ ~ ~