README.1ST
Book Versioning
The Synapticloop Panl project uses semantic versioning - i.e. major.minor.micro, with the following rules:
- major - the major version will increment when there is a BREAKING CHANGE to the Panl LPSE URL generation, a BREAKING CHANGE to the Panl response JSON Object, or a MAJOR UPDATE TO SOLR. Upon increment of the major version, both the minor and micro version number will be reset to 0 (zero).
- minor - the minor version will increment when there is additional functionality added to the release. Upon increment of the minor version, the micro number will be reset to 0 (zero).
- micro - the micro version will increment for bug fixes only.
The book version always matches the release version of the Synapticloop Panl server code version. Any changes to the book without any changes to the underlying codebase will be updated on the main branch and the website based on the ghpages GitHub branch will be updated.
The book release number will be updated on change i.e. Version 2.2.0 (Release 1) will become Version 2.2.0 (Release 2).
Any Panl release packages on the GitHub release page will only include the version of the book that was available at the time of the code release.
Solr Schema Versions
This book uses a Solr schema version of 1.6 (i.e. the version attribute in the managed-schema.xml file), which covers Solr server versions from 7.7.3 (and possibly earlier versions) up to 9.6.* to provide greater coverage of Solr versions. The examples in this book, especially around faceting, will behave differently on Solr version 9.7.0 upwards if the schema version is set to 1.7.
There are two options:
- Use a Solr managed-schema.xml file from a previous version as is done in this book, or
- Use the updated schema version, but be aware of the differences in the return of faceted information - see the section on the differences between the schema versions The Impact Of docValues (Solr Schema Version 1.7+)
|
|
IMPORTANT: The examples in this book will still work as expected, just be aware that the schema version used in the examples are from a previous Solr version.
This was deliberately done to ensure compatibility with the widest range of Solr implementations. When Solr version 10 is released, the schema version may change to version 1.7. |

About This Book
This book describes and explains the functionality of the Panl server, how to configure the server, and how this impacts the generated URL paths.
To start with, this book will take you through setting up and running a new Solr instance in cloud mode, creating a new collection, and indexing the included sample data. Then the Panl server will be started with the sample configuration and the functionality of the results and facets can be viewed with the in-built Panl Results Viewer web application.
The book then continues to explain the details of configuring the Panl server, with the assumption that there is already a running Solr instance behind it. This will take you through all the various configuration options so that you can implement your faceted search pages and associated URLs that are tailored to your specific requirements.
This book is not designed to be an introduction into Solr configuration, administration, or schema design best-practices, however there are hints and tips throughout the book which may be of interest. These hints and tips relate to items that will affect the results that you retrieve from the Panl server, Solr configuration, and the integration and implementation.
Nomenclature Used Throughout This Book
When implementing any faceted search interface the following terms are the foundation and are used throughout the book:
Attributes
Attributes are information that is attached to each document. For example if you were searching on mechanical pencils (as the example shows in this book), the attributes of a mechanical pencil include the brand, model name, colour, whether this pencil has an in-built sharpener, length, weight, and many others.
Documents
Solr nomenclature for the individual result that is indexed and that can be returned by the Solr search. You can also think of these as the rows of results that will be returned.
Facets
Facets are specific attributes that are extracted from the data and are attached to the index. Each of these attributes can then be used to filter the results such that only the documents that contain those attributes are returned. The image below shows the different parts of the facets (including information that Panl includes in the returned object).
Image: A snippet of the Panl Simple Results Viewer showing the 'Mechanism Type' facet and describing the parts of the returned facet information
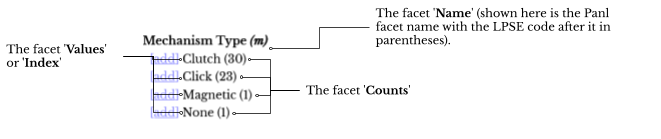
In the above image:
- The Solr field name (which is not shown in the image above) is mechanism_type, the Panl name is being rendered to the page i.e. 'Mechanism Type' , the (m) after the name is the Panl LPSE code, the [REGULAR] is the type of facet that is configured within Panl. This information is output for reference in the Panl Results Viewer web app and can be omitted (or kept) in your implementation.
- The facet values represent the indexed attribute values that are attached to the document, they are:
- Clutch
- Click
- Magnetic
- None
- The facet counts represent the number of documents that contain these values, respectively they are:
- 30
- 23
- 1
- 1
- The 'add' link is generated by the Panl Simple Results web app from the returned JSON results object. This link is in the Panl LPSE form.
Keyword search term
The text (either a word or phrase) that is submitted from a form on the web page through to the Panl server, which is passed to the Solr search server to query against the collections' indices. (also known as 'search query', 'search term', 'search phrase', or some other combination or words).
Additional introductions to common words and phrases used throughout the book are below. Terms and names are generally defined where they first appear, for a full list - see the Appendices - Definitions at the end of the book.
CaFUPs
An acronym for Collection and FieldSets URL Paths - Panl allows many different groups of fields (the FieldSet) to be bound to a specific Solr Collection. Each CaFUP has a unique URL that is served by Panl.
CaFUPs allow you to configure multiple ways in which the search results and fields are returned for any specific Solr Collection.
Collection(s)
There are two types of collections referenced in this book, the Solr Collection, and the Panl Collection.
Solr collections are an index of documents that can be filtered or searched upon. This collection is served from the Apache Solr search engine
Panl collections are collections of URL paths and FieldSets - that are configured to connect to a Solr collection with defined returned fields.
LPSE codes
The foundation of how the Panl server decodes and parses a URL path to convert it to a form that the underlying Solr server can understand. A LPSE code is either a number, or an uppercase or lowercase letter of the alphabet (i.e. a-z, A-Z, 0-9). These codes are placed in the last path part of the URL.
LPSE path
The LPSE path is a string of URL path values, which, in conjunction with the LPSE codes above, is how the Panl server decodes the URL and transforms it into a Solr server query.
Panl field
This is the field definition that contains the configuration that determines how this field is mapped to the Solr field and what translations should be done on the incoming value before passing it through to the Solr server.
Panl generator
A stand-alone utility to quickly generate a panl.properties file and <panl_collection_url>.panl.properties file from an existing Solr managed schema file that can be used as a starting point for configuring the Panl server.
NOTE: The generator does not interact or interfere with the Panl server and the generator codebase is not used when serving production content.
Panl name
This is the nicer, human-readable field name that the UI can display in preference to the Solr field name
Panl server
The server that responds to specific URLs, parses the URL path, builds the Solr request object, connects to the Solr search server, executes the query, parses the results, builds the JSON response and passes it back to the caller.
Solr field
The definition of the field in the managed-schema.xml Solr configuration file which determines how Solr indexes, searches, and presents the information. The Solr field type determines what features can be configured to be used by the Panl server.
Solr query
The HTTP query string that is sent to the Solr search server, an example of this is:
q=*:*&q.op=OR&facet.limit=100&fl=brand,name&facet.mincount=1&rows=10&facet.field=le
ad_size_indicator&facet.field=colours&facet.field=brand&facet.field=mechanism_type&
facet.field=hardness_indicator&facet.field=lead_grade_indicator&facet.field=in_buil
t_sharpener&facet.field=disassemble&facet.field=category&facet.field=lead_length&fa
cet.field=in_built_eraser&facet.field=grip_shape&facet.field=weight&facet=true&fq=i
d:"53"&start=0
(Panl's entire raison d'être is to abstract this away from the implementers and end-users.)
Solr search server
The Apache Solr search server that is queried for results.
Tokens
Tokens are Panl internal representations of the incoming LPSE code and any associated URL path values for each of the codes. Tokens will be parsed, prefixes and suffixes removed, and validation performed on the incoming value. If any parsing or validation fails, then the token will be marked as invalid, ignored, and not passed through to the Solr server.
Book Format Conventions
Normal Text
Normal paragraph text is Libre Baskerville, 11pt, other formatting conventions are detailed below.
Sidebars
|
|
IMPORTANT: Important notes are within a red side-bordered box, with an exclamation icon, and red background. Careful note should be made of the information contained within these boxes as this will affect the running of the Panl server, and there may also be non-obvious side-effects. |
|
|
Notes: Notes are within a black side-bordered box, with a pencil icon, and grey background. This is something to look out for when you are reading the book, executing a task, or looking at an image or URL. |

|
|
Tips: Tips are within a black bordered box, with a lightbulb icon, and white background. This is something which is a handy idea to know for the functioning or configuration of the Panl or Solr servers. |
Code / Output Related Snippets
Inline code, or text related snippets are in monospaced text (Inconsolata Normal 11pt), and highlighted in grey, for example: /Caran d'Ache/true/Black/bDW/. This indicates that the text is exact and should be used as a reference.
For multi-line code or text related snippets (including console and logging output) the text appears in a black-bordered grey box prefixed by a line number so that they can be referenced within the description text.
|
|
Note: that within any line, there may be a line continuation character (↩) which should not be included in the command. Unfortunately, for electronic viewers this means that it is a little more difficult to simply copy and paste the text - apologies, however readability and explanation of the text over cut-and-paste-ability. |
|
01
02 03 |
# The text file that may be included, with some information or processing ↩ # a line of commented text # this is another line of text |
Commands
Any commands that should be run in your terminal or command line prompt will appear in a formatted table with a white header on a dark grey background. Note the '↩' character which means a line continuation and should not be included in the command. (Reasoning is as per above with the copy and paste-ability of the lines).
|
Command(s) |
|
\the\command\that\needs\to\be\run -with "a parameter" -and-another ↩ |
Links
Links are designated by underlining the text of the link. If the text is underlined, it is either a link to an external website, or another section of this book.
External links to websites (either local or remote) are in the standard blue underline, indented, and will ALWAYS match the URL that will open in your browser (i.e. the URLs are never truncated, even if they take multiple lines):
Links to other sections or chapters within this documentation are bold, underlined, and in black text and always match the heading text:
Integrating An Existing Solr Schema
Images
Images are bounded by a dotted border inside a bordered section with a caption.
|
|

Footnotes[1]
Footnotes aren't used very often, but when they appear they can be safely ignored - these are more background thoughts as to why things were implemented the way they were. This will not impact the running of the Panl Server.
~ ~ ~ * ~ ~ ~