Afterword
Firstly, my sincerest thanks for getting this far through the book. I found it quite pleasurable (most of the time) to write, and I hope that you have had the same experience reading it.
Secondly, you do not need to read any of this chapter, this delves deeper into the entire process and project behind the Panl server.
That being said, my most fervent wish is that you find the Panl project to be useful.
On The Tag-Line
A rather pleasing companion to the Apache® Solr® Faceted Search Engine.
I wrote this line as a first draft with a definite understated tone. Although, as I progressed through writing the book it resonated more with me. Firstly, I do not like to emphasise my skills or work - believing the work should speak for itself, so it fits nicely with my personal views on life. Secondly, the Panl project implementation should be understated, something which sits in between a web app and the Solr Search server and just happily does its job, hidden between the layers.
I also like the name Solr Panl, it has a certain ring to it - the original tagline at project inception in 2008 was "Panl - soaking up the Solr goodness".
On Documentation
My view on documentation is that it is something that everyone loves to consume, but few people like to produce. And when I use the word 'documentation', it comes in many sources, from the actual source code and tests of a project, to the generated documentation, the StackOverflow posts, the Search Engine searches, the blog posts, videos, and books, and, of course, the munged version that is AI.
The thing about writing documentation of any type, is that it makes you a better engineer/developer/coder and leads back to questioning your design principles and architecture. I have never had any hard and fast rules around architecture and some of the decisions made in coding the Panl project was to make the implementation and integration easier for the engineer when it came to parsing the JSON results and debugging/testing through the Panl viewer and explainer web apps. This led to some design decisions which coupled the code far too tightly - which, in some cases, was a deliberate decision.
I am a firm believer in ease of understanding and implementation over architectural purity.
Documentation can be time consuming and difficult to do - perhaps this is why documentation can be such a low priority for people, and it can be a grind to get through, constantly writing and updating text and formatting, adding in new features and having to revise the entire book to ensure that everything gets updated and referenced properly.
Just by writing this book, by having to explain how it all fits together, new ideas and ways of doing things have come to my mind, which leads to even more edits of the book.
When you have to explain a decision to someone, or how something works, you are given a second chance to review what you have created, and have to put yourself in the shoes of the reader/implementer and ask yourself the same questions about what you are doing. Questions such as:
- Why did you decide to do things this way?
- Would I be able to change the way it is done?
- How can I configure it to do this?
- What about if I want my search results page to work like this?
It also means that you are not as easily able to hide functionality that should be there but isn't, by not including something you are publicly saying that you:
- Didn't know about it, or
- Couldn't be bothered to implement it, or
- Hoped that people wouldn't notice.
From this perspective I have changed the underlying code and features and functionality that is present within the Panl server. Some of the changes include
- Not having a configurable /panl-results-viewer/ and /panl-results-explainer/ URL path, instead you may either turn on or off this functionality. This would have been a straightforward change, but the benefits were slight, new properties would have to be added, and this only occurs if there is a collection named exactly panl-results-viewer, or panl-results-explainer.
- Implementation of pass-through (or ignored) URL paths - and the additional property for keeping this token in the canonical URL generation.
- Less verbose 404 and 500 error messages
- Translation of boolean fields from true or false to something more human readable
- Added in DATE Range facets
- Highlighting, although in this instance I deliberately chose a subset of functionality to implement
- Hierarchical facets, only displaying a facet and its value if another facet has already been selected.
- Better way of implementing OR facets in the way that they work.
- Sorting of facets by (to use Solr nomenclature) index or count.
- Specific Solr Search Fields
- More Like This
All of this has made the product a better one, and if nothing else, I thoroughly recommend writing a book, or at the very least a HOW-TO on whatever project you are working on.
On This Book
From a book perspective, what started as a 281 page (or 52,000 word) book has now ballooned (or perhaps blossomed is a better word) to over 600 pages and over 100,000 words. Knowing every line of code and configuration is one thing, explaining and documenting it is another. Setting the right level for the novice and seasoned professional is difficult, however, I chose to go down the 'rather detailed' path, rather than leaving anything out.
It still is a moving target, and as I write the book, (especially now that version 2.2.0 has been released) new bits of functionality come to mind and I wanted the version 2.2.0 release to contain almost everything doable on my wish-list. That being said, the time it takes to write the book has given me excellent thinking time about future features and about how to implement them whilst keeping them documented.
The challenge becomes updating the book to ensure that every new feature and functionality is correctly added and documented in the myriad of places that it may appear is very time consuming, and I am reluctant to release a new code package without the associated book version being up to date.
Keeping the code, properties, JSON objects, and anything related to the source or output is still very, very annoying with a lot of copy and pasting and reformatting having to be done. This is especially true as the book was written with Panl version 1.0.0 and has gone through multiple changes to version 2.2.0, all the while, the Solr versions have changed from 9.6.1 to 9.7.0, to finally 9.10.0 which have changed command line parameters and schema versions. Having an underlying moving target (Solr) with an overlay of a moving target (Panl) makes it a little difficult.
All in all, the book is the one thing that I know keeps the code well documented. And that is a good thing.
Additional Functionality in the Pipeline
The codebase for this project started in 2008, with updates and some usages, now after languishing for a long time, 16[53] years later, it has come a long way, and a release was produced. Not all features and functionality made it into the code base, some from time and effort of implementation, some from documentation, and finally, something just had to be produced and put out into the wide world.
In general it came down to drawing a line under the current functionality, after all...
Code is never complete, it is just abandoned.
Issues, feature enhancements, and bugs are now kept in the GitHub issues section:
https://github.com/synapticloop/panl/issues
Real Life Implementations
The great thing about having a tool that works and has been iterated over is being able to spin up some Panl servers and utilise it for real-life projects and implementations. With every new real-life implementation more functionality is added to the Panl server to suit individual use-cases as and when they become applicable.
There is something extremely satisfying when spinning up a new Panl instance where it just works as expected.
For every implementation, the process is the same
- Access the data - be it a datastore of some sort, web based APIs, or crafted by hand.
- Index the data
- Apache Tika is an excellent Java based file parser which enables indexing of a wide variety of formats
- Python OCR through pytesseract takes a little bit of set up but does an excellent job
- The Node.js libraries for converting Microsoft Office based files (to HTML and PDF) are particularly straight-forward
- Present the Results, including building the results pages
- Large Document Repositories
As part of handover of buildings and companies, a large amount of documents of all types were ingested and enabled to be searched and faceted on to narrow down the results to the exact document.
- Apache Tika based file type indexing
- Python based OCR on images to add to the index
- Automatic pickup of index files to map file names and categories
- Directory based categorisation
- Date Range facets with derived month and year facets
- In-built Panl Results Viewer web app for front-end UI
|
|

- Mechanical Pencils
This is what kicked this project back into gear, being able to index, organise, facet, and visualise the different types of mechanical pencils.
- Hand built dataset in JSON
- Ingest images from two additional projects
- Static site generated from Java based web app and recursively spidered to the file system
|
|
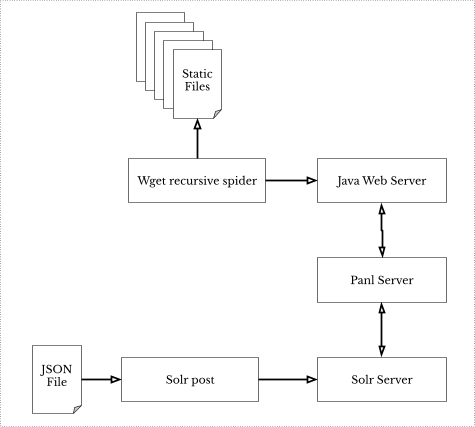
- Policies and Procedures
For legislative requirements, all policies and procedures were indexed to all staff to find the correct document, rather than searching through a file system and reading the file names.
- File system watching for new files to index on addition, and re-index on change
- Node based pickup of changed and added files to create PDF representations
- Node based pickup of changed and added files to convert to HTML for modal window
- Front end UI delivered in Node.js express web application
Image: The high level architecture for the Policies and Procedures files.
- Government Legislation
Rather than searching through the dry and verbose PDF files that the government produced for legislation, Panl was implemented with full keyword search and facets across the complete set of legislation.
- Parsing of XML[54] content to extract details
- Indexing of text in Solr
- Extraction of parts, sections, references, and others for
- Panl in-built Results Viewer web app for browsing, searching and faceting of results
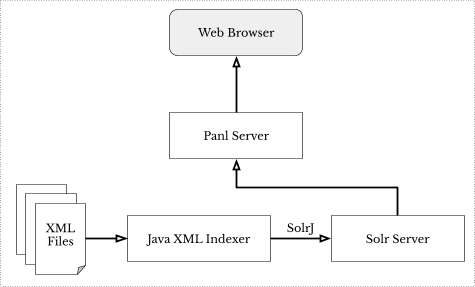
Image: The high level architecture for the Government Legislation XML files.
~ ~ ~ * ~ ~ ~
In any case, I hope that you enjoy - and more importantly, implement and use - the Panl server for your Solr search server implementation.
~ ~ ~ * ~ ~ ~