Putting It All Together (Technically)
Panl was not specifically designed to be web facing, although it could be should you so choose. The recommended way is to hide the Panl implementation CaFUPs URL and proxy them through a web or application server.
A number of Panl servers can be spun up at the same time (on different ports if on the same server) and load balanced between them. There is no state to be kept between requests, so it is lightweight and fast.
A Brief Architecture
Image: The recommended approach to integrating the Panl server
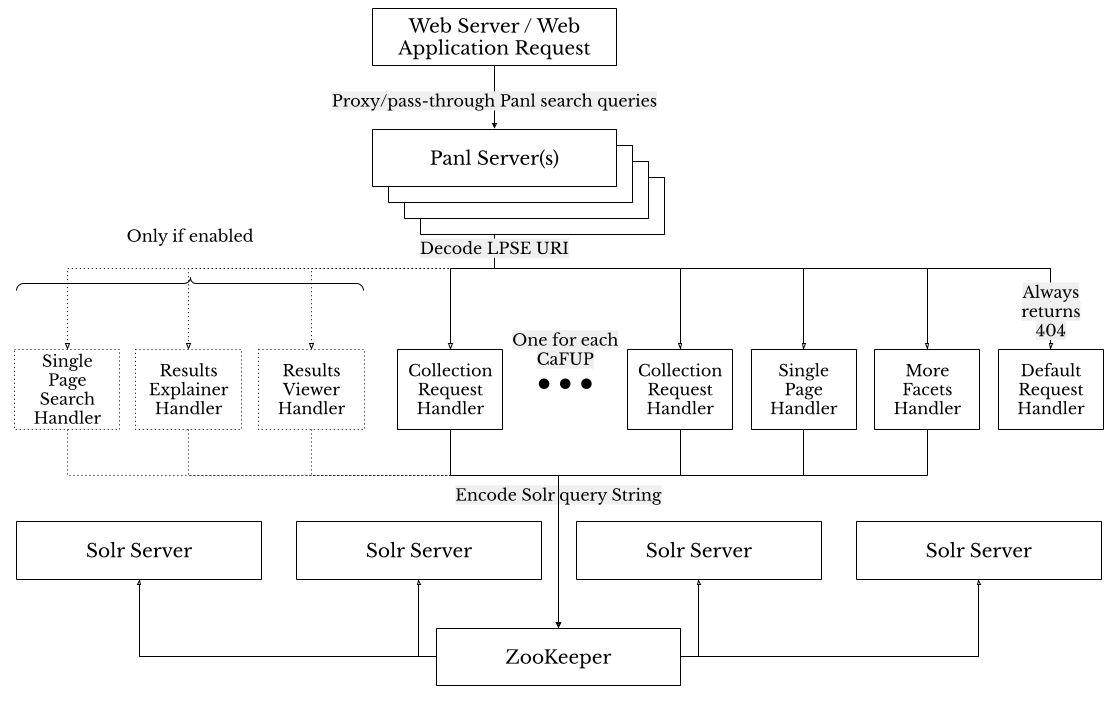
In the above diagram, the incoming request hits the front end web/app server, is proxied through to the correct Panl CaFUP which is then handled by a Collection Request Handler. The URL path part is decoded and parsed, the query built, sent to the Solr server and the response built and returned.
You may wish to open the Panl server to external requests, however, be aware that there are no authentication or authorisation mechanisms in the Panl server. See the section on Is Synapticloop Panl For Me? to inform your decision.
Production Readiness
- Turn off in-build Panl testing URLs,
Set the property panl.results.testing.urls=false in the panl.properties file - Turn off verbose 404 and 500 HTTP status responses,
panl.status.404.verbose=false
panl.status.500.verbose=false - Finally, check the logging requirements (see heading below).
Edit the log4j2.xml file to your requirements.
Logging
Panl utilises the log4j2/slf4j framework for all its logging and the Panl server does not log excessively. The parts of logging that the Panl log4j2 configuration performs is:
- INFO level startup logging which logs informational messages about the Panl configuration and URL bindings at startup,
- DEBUG level logging for inbound Panl token decoding and validation,
- DEBUG level logging for the query string that is passed through to the Solr server, and
- ERROR level debugging for HTTP status 500 Internal Server Error (with stacktraces).
The most up-to-date logging configuration file can always be viewed on the GitHub repository:
https://github.com/synapticloop/panl/blob/main/src/main/resources/log4j2.xml
The in-built logging configuration is set up for development use, with the Solr query being output to debug the state of the URL tokens. A copy of the file is included below:
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
<?xml version="1.0" encoding="UTF-8"?> <!-- ~ This is the default logging configuration file for the Panl server which ~ does not do too much. ~ ~ Panl does not log too many things, just startup and the incoming requests ~ and validation ~ -->
<Configuration status="WARN"> <!-- ~ This is the root logger which just logs the INFO messages to the ~ console, which are the generic startup messages. --> <Loggers> <Root level="info"> <AppenderRef ref="console"/> </Root>
<!-- ~ The Panl request handlers log on the debug level for the incoming panl ~ token validation and the transposed Solr query that is executed. To ~ remove this logging, comment out the following Logger, or just delete ~ it. --> <Logger name="com.synapticloop.panl.server.handler" level="debug" additivity="false"> <Appender-ref ref="console" /> </Logger> </Loggers>
<Appenders> <Console name="console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{2} - %msg%n"/> </Console> </Appenders> </Configuration> |
Setting the Logging Configuration and Levels
The logging configuration file is located in the release package with the name PANL_INSTALL_DIRECTORY/lib/log4j2.xml.
For the logging system to be configured correctly, when invoking the Panl server from the command line, Panl will look in the current working directory first for a file named log4j2.xml, it will then look for the file in the lib directory (i.e. ./lib/log4j2.xml).
If it cannot find the file in either of the above locations, Panl will use the in-built logging configuration file (as shown above) from the classpath which is contained within the ./lib/panl-.x.x.x.jar - where x.x.x is the version number for the Panl server.
On startup, the Panl server will output statements with [LOGGING SETUP] to log where the Panl server is searching for the log4j2.xml configuration file.
|
01
02
03
04
05 07 |
[LOGGING SETUP] Could not find the file located ↩ 'C:\Users\synapticloop\java-servers\panl\.\log4j2.xml'. [LOGGING SETUP] message was: .\log4j2.xml (The system cannot find the file ↩ specified) [LOGGING SETUP] Could not find the file located ↩ 'C:\Users\synapticloop\java-servers\panl\.\lib\log4j2.xml'. [LOGGING SETUP] message was: .\lib\log4j2.xml (The system cannot find the path ↩ specified) [LOGGING SETUP] Could not find a log4j2 configuration file. See messages above... [LOGGING SETUP] If available, log4j2 will use the configuration file from ↩ the classpath. |
Upgrading Your Panl Server Version
Upgrades to Panl are designed to be as seamless as possible with the underlying properties file designed to be drop-in replacements when upgrading to a new version.
Breaking Changes
Any breaking changes to either the Panl JSON object, or the LPSE URL will increment the major version of the Panl release package (i.e. version 1.x.x to 2.x.x). On some occasions, the Panl major version will be updated if there is a major update to the Apache Solr server - for example the release of Solr version 10 which increments the minimum requirements for the JVM to run upon.
LPSE URL Changes
Changes to the LPSE URL will impact any links that you have created and published.
Panl JSON Response Object
Changes to the Panl JSON response object will impact your integration points with your application and will most probably require testing and updating depending on the functionality that you have implemented.
Generating SEO Friendly URLs
Going beyond the in-built features of the Panl configuration, to generate URLs - especially those with a passthrough parameter may require additional application integration.
You could either go to the datasource (e.g. a database) and build the URLs programmatically, or let Panl generate all URL paths, and/or a combination of both.
Data Dependencies
Using the original datasource to generate links will create a dependency on the Panl configuration, and should the Panl configuration change, then the links may not still be valid.
For example, if you generated links for the mechanical pencils collection from a datasource as
/Manufactured by Koh-i-Noor Company/b/
And the Panl configuration changed to generate the path:
/fine-pencils-by-Koh-i-Noor/b/
Then Panl would not return any results as the prefix and suffix did not match and this facet would not be passed through to the Solr server.
Panl is designed to statically generate URLs, so a simple web-crawler/spider will enable the complete resultset to be generated and written to the filesystem - be aware that due to multiple facets and options, this may generate a rather large number of pages.
To generate individual static pages, a separate CaFUP could be registered and just a subset of the pages indexed.
Passthrough URLs
Passthrough URLs are a little more able to withstand Panl configuration changes as they are not linked to any Solr field value.
Passthrough URLs are also best used to link to a single document, or a subset of documents. For example, in the Bookstore dataset, the following link uniquely identifies a book (using the ID field from Solr):
http://localhost:8181/panl-results-viewer/book-store/default/4/i/
And consequently any passthrough parameter will give the same result, such that
and
Return the same result.
When using passthrough URLs, you may wish to configure a separate file and associated CaFUP just for these values, and be able to tweak other configured CaFUPs.
Standalone Solr Installations
Not every use-case requires a cloud enabled Solr server setup. Whilst running a cloud offers various benefits with resiliency and uptime, there may be implementations that do not require the added overhead of CPU, disk, and memory requirements.
When running in standalone mode, no ZooKeeper instance is available, which impacts the creation of the collection in Solr.
What Does ZooKeeper Actually Do?
Apache ZooKeeper serves as the centralised service for a Solr cloud deployment, it centralises:
- configuration management for Solr (e.g. solrconfig.xml, managed-schema.xml, stopwords.txt etc.)
- handling distribution of configuration to all Solr nodes,
- maintaining cluster state - including information about
- live nodes,
- shard and replica assignments, and
- facilitates leader elections for each shard.
The Impact of Not Having a ZooKeeper Deployment
In cloud mode for Solr 9, when a collection is created through the command line, the Solr configuration files are uploaded to the ZooKeeper instance, which then distributes it to the Solr nodes.
In standalone mode, there is no ZooKeeper instance, so the 'uploading' and creating of the collection requires a different process, with additional steps.
|
|
Notes: Creating the configuration in Solr version 7 in cloud mode is not automated as it is in version 8 and 9 in that the configuration must be uploaded to ZooKeeper first as a separate step - i.e. the command: bin\solr zk upconfig -d ↩ PANL_INSTALL_DIRECTORY\sample\solr\mechanical-pencils -n mechanical-pencils ↩ -z localhost:9983
Is required to be run to create the collection. |

Creating and Running a Standalone Solr Instance
The same Solr release package can be used - in this example the solr-9.10.0-slim package was used.
To run the Solr server in standalone mode use the switch --user-managed which will run a single server on port 8983.
Step 1 - Create a Standalone Solr Instance
Start the server in 'Standalone' - i.e. 'User Managed' mode - Note the command line argument of --user-managed.
Windows
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
bin\solr start --user-managed |
*NIX
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
bin/solr start --user-managed |
Step 2 - Create the Directories
Both the data and instance directories must be created before the collection can be created.
The instance directory is where Solr will store the configuration files and indexed documents. Whilst two directories must be created, only one will be used.
Windows
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
md mechanical-pencils md server\solr\mechanical-pencils |
*NIX
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
mkdir -p mechanical-pencils mkdir -p server/solr/mechanical-pencils |
|
|
Note: The first directory that is created __MUST__ exist, but it is not used, all configuration and data is placed in the server/solr/mechanical-pencils directory. |
Step 3 - Copy the configuration
Rather than passing through the configuration directory as was done when the Solr cloud instance was started, the Solr standalone server must have its configuration within the Solr server directory.
Copy the sample mechanical pencils configuration files from
sample/solr/mechanical-pencils
to the
SOLR_INSTALL_DIRECTORY/server/solr/mechanical-pencils
directory.
Step 4 - Upload the Configuration
This will take the previously copied configuration files and upload the configuration to the Solr server.
Windows
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
bin\solr create -c mechanical-pencils -d mechanical-pencils |
*NIX
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
bin/solr create -c mechanical-pencils -d mechanical-pencils |
Step 5 - Index the data
The indexing of the data is an identical process to indexing a Solr cloud deployment.
Windows
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
bin\solr post -c mechanical-pencils ↩ PANL_INSTALL_DIRECTORY\sample\data\mechanical-pencils.json |
*NIX
|
Command(s) |
|
cd SOLR_INSTALL_DIRECTORY
bin/solr post -c mechanical-pencils ↩ PANL_INSTALL_DIRECTORY/sample/data/mechanical-pencils.json |
Step 6 - Update the panl.properties file
As you are no longer connecting to a Solr server in cloud mode, the panl.properties file will require configuration changes.
Change the following properties
from:
solrj.client=CloudSolrClient
to:
solrj.client=Http2SolrClient
And from:
solr.search.server.url=http://localhost:8983/solr,http://localhost:7574/solr
to:
solr.search.server.url=http://localhost:8983/solr
~ ~ ~ * ~ ~ ~