A Brief Introduction To Solr
This chapter covers the minimal information that is required to understand the integration points between the Solr and Panl servers. Many books, articles, blog posts, sites, and information has been written and published on the Apache Solr project and server which are useful for understanding and fine-tuning the Solr search server, this chapter will not go into enough detail to even come close to replacing those resources.
Querying Data
For any search engine, there are two ways to query the data, either through a keyword search, or through faceting, which makes presenting relevant facets that span the large number of different types of results.
Below is an image of the DuckDuckGo search engine which allows both a keyword search and some very simple faceting options.
Image: A DuckDuckGo search with the keyword of 'Solr Panl' which will show relevant results and some simple faceting options.[13]

Large scale web search engines attempt to index and make sense of the huge amount of data that is available on the myriad of websites.
Apart from the keyword search of 'solr panl', the following facets are available to a search:
- Country of origin (set to 'United Kingdom'),
- The safety of the search results (set to 'moderate'), and
- The time that the content was published (set to 'Any time')
The facets will help to guide the search results, but they are broad facets which are useful for this interface. Note: that there are advanced options to only search one site, or to search the file type as well.
With smaller and more well-defined search results, there is greater potential to add facets that help the user get to the correct details more quickly.
Individual sites use search keywords and more targeted and relevant faceting to help guide their users.
The Solr Managed Schema
Included within the downloaded Panl release is an example managed schema file for the mechanical pencils collection.
PANL_INSTALL_DIRECTORY/sample/solr/mechanical-pencils/managed-schema.xml
For the Solr server version 9 - this file can also be viewed on the GitHub repository:
Whilst there are many configuration options within the schema file, this file has three major parts of interest to the Panl server, namely:
- The schema name attribute on the top level element (<schema name="mechanical-pencils" />) which is configured to map to the Panl collection URL name,
- The field definitions including the fields type (<field /> elements) which may either be facets or fields, and
- The field type definitions (<fieldType /> elements) which drive validation and in place text replacements for the Panl server
In this file formatting added for readability, which means that the original schema file line numbers will not match the below:
|
01 02 03 04
05
06
07
08
09
10 11 12 13 14 15 16 17 18 |
<?xml version="1.0" encoding="UTF-8" ?> <schema name="mechanical-pencils" version="1.6"> <field name="_version_" type="plong" indexed="false" stored="false"/> <field name="id" type="string" indexed="false" stored="true" required="true" ↩ multiValued="false" /> <field name="brand" type="string" indexed="true" stored="true" ↩ multiValued="false" /> <field name="disassemble" type="boolean" indexed="true" stored="true" ↩ multiValued="false" /> <field name="description" type="text_general" indexed="true" stored="true" ↩ multiValued="false" /> <field name="manufacturer_link" type="string" indexed="false" stored="true" ↩ multiValued="false" /> <field name="colours" type="string" indexed="true" stored="true" ↩ multiValued="true" />
<!-- additional field definitions -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" /> <fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<!-- additional field type definitions -->
</schema> |
Line 1:
Is the standard XML definition
Line 2:
The start of the schema definition for the mechanical-pencils data. Note: The schema's XML elements name attribute (i.e. name="mechanical-pencils") will be used by the Panl generator as the filename for the <panl_collection_url>.panl.properties file and for the property name. For the above example schema file, it will generate a properties file name mechanical-pencils.panl.properties, and place a property in the panl.properties file of
panl.collection.mechanical-pencils=mechanical-pencils.panl.properties
|
|
IMPORTANT: When creating a collection in the Solr server, (i.e. by having a panl.collection.<solr_collection_name>=<panl_collection_url>.<properties_file_name> in the panl.properties file, the <aolr_collection_name>) part of the property key __MUST__ match the Solr collection name to connect to. The <properties_file_name>, may be any name, noting that the <panl_collection_url> first part of the file name is the URL path that the Panl server will respond to, and __MUST__ be unique amongst all URL paths registered by the Panl server.
For example, the following line in the panl.properties file:
panl.collection.mechanical-pencils=mechanical-pencils.panl.properties
Will be parsed as follows:
The Solr collection name of mechanical-properties will be taken from the property key: panl.collection.mechanical-pencils
Panl will read the configuration from the properties file and will use the first prefix of the filename to bind the Panl URL path to, for the above example the URL path would be mechanical-properties/*
brands/* |

Lines 3-9:
These are the field definitions, seven fields are defined in the above example, there are many more fields in the actual managed schema file.
- _version_ - required by Solr - this is an internal field that is used by the partial update procedure, the update log process, and by SolrCloud.
- id - this is the identifier of the result, and must be unique across the collection.
- brand - the field that stores the brand of the mechanical
- disassemble - the field that stores whether the mechanical pencil can be easily disassembled.
- description - the field that stores the description of the pencil
- manufacturer_link - the field that stores the link to the manufacturer of the mechanical pencil
- colours - the field that can store multiple colour values for the specific mechanical pencil.
The impact of field definitions and field types on the Panl server
The two basic rules for Solr field definitions are:
- If a field is indexed (indexed="true") then you will be able to search on the field contents, sort by this field, and use the field contents as a facet, and
- If a field is stored (stored="true") then you will be able to return this field in the search results documents, and be able search on the field, but cannot be used as a facet (unless it is also indexed)
Line 11:
For brevity, additional field definitions were removed and replaced with a comment.
Lines 13-14:
Solr field type definitions, which the Panl generator will look for to determine how validation and prefix-suffix replacement will be done.
Note the solr.BoolField will also allow boolean value replacement (along with optional prefixes and suffixes).
Line 16:
For brevity, additional field type definitions were removed and replaced with a comment.
Line 18:
The end of the Solr managed schema.
Determining the Appropriate FieldType and Attributes
A quick overview of the decisions around choosing the field type, and setting the :
Image: The decision chart for determining the field types and attributes
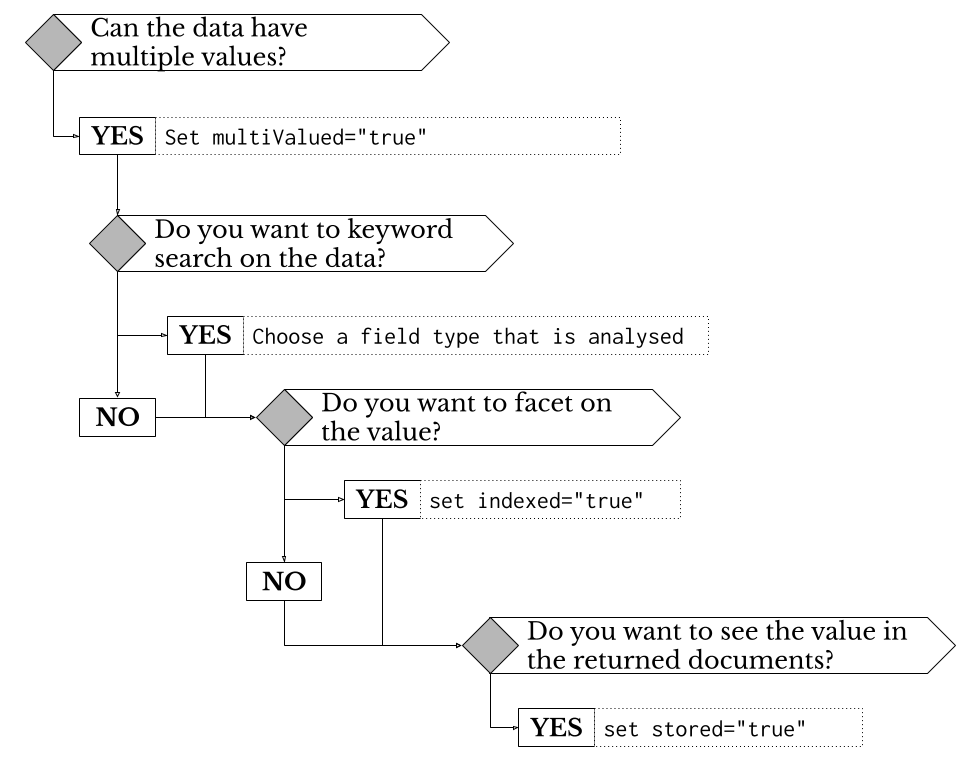
There attributes for every field definition in the Solr managed schema are as follows:
- name - the Solr field name for this piece of data
- type - the type of the data to be indexed, this will determine the configuration options that are available through the Panl server. Note: this 'type' is used to reference the Solr field type. It is this field type that determines how it is to be indexed by Solr.
- indexed - whether to index the data so that it may be searched/faceted upon
- stored - whether the data will be stored in the Solr index and available to be returned with the results documents.
- multiValued - whether this field may contain more than one value
For example:
In the sample file, the brand field is configured as a type of string
|
01 |
<field name="brand" type="string" indexed="true" stored="true" ↩ |
The value of the type attribute is then mapped to a Solr class. Further down the Solr managed schema file are the definitions of the field types which match the above type attribute (I.e. the type of the field above, matches the name of the fieldType's name attribute below). For the above field, the matching fieldType definition is below.
|
01 |
<fieldType name="string" class="solr.StrField" sortMissingLast="true" /> |
This will return the facet values for the brand data as they are and stored. With NO ANALYSIS done on the fields.
They will be displayed on the Panl Results Viewer:
http://localhost:8181/panl-results-viewer/mechanical-pencils/brandandname
And return the facets values in full (including the configured prefix and suffix):
Brand (b)
- [add] Manufactured by Koh-i-Noor Company (11)
- [add] Manufactured by Caran d'Ache Company (4)
- [add] Manufactured by Faber-Castell Company (4)
- [add] Manufactured by Pacific Arc Company (4)
- [add] Manufactured by Alvin Company (3)
- [add] Manufactured by Kaweco Company (3)
- [add] Manufactured by Rotring Company (3)
- [add] Manufactured by Hightide Penco Company (2)
- [add] Manufactured by Kita-Boshi Company (2)
- [add] Manufactured by Küelox Company (2)
- [add] Manufactured by Mitsubishi Company (2)
- [add] Manufactured by OHTO Company (2)
- [add] Manufactured by Scrikks Company (2)
- [add] Manufactured by Staedtler Company (2)
- [add] Manufactured by BIC Company (1)
- [add] Manufactured by DEDEDEPRAISE Company (1)
- [add] Manufactured by Ito-Ya Company (1)
- [add] Manufactured by Mr. Pen Company (1)
- [add] Manufactured by Muji Company (1)
- [add] Manufactured by Redcircle Company (1)
- [add] Manufactured by Unbranded Company (1)
- [add] Manufactured by WSD Company (1)
- [add] Manufactured by YStudio Company (1)
In contrast, if the brand field was configured as text_general
|
01 |
<field name="brand" type="text_general" indexed="true" stored="true" ↩ |
The fieldType definition includes an analyser which will break up the text into individual words and lowercase them, and ignores stopwords:
|
01 02 03 04 05 06
07 08 09 10 11 12 13 14 15
16 17 18 |
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer name="standard"/> <filter name="stop" ignoreCase="true" words="stopwords.txt" /> <!-- in this example, we will only use synonyms at query time <filter name="synonymGraph" synonyms="index_synonyms.txt" ignoreCase="true"↩ <filter name="flattenGraph"/> --> <filter name="lowercase"/> </analyzer>
<analyzer type="query"> <tokenizer name="standard"/> <filter name="stop" ignoreCase="true" words="stopwords.txt" /> <filter name="synonymGraph" synonyms="synonyms.txt" ignoreCase="true"↩ <filter name="lowercase"/> </analyzer> </fieldType> |
This will break up the facet values into individual, lower-cased words and return the analysed facet values for brand and display the following facet list: (Note: that this configuration is not included in the sample configuration)
Brand (b)
- [add] i (11)
- [add] koh (11)
- [add] noor (11)
- [add] arc (4)
- [add] caran (4)
- [add] castell (4)
- [add] d'ache (4)
- [add] faber (4)
- [add] pacific (4)
- [add] alvin (3)
- [add] kaweco (3)
- [add] rotring (3)
- [add] boshi (2)
- [add] hightide (2)
- [add] kita (2)
- [add] küelox (2)
- [add] mitsubishi (2)
- [add] ohto (2)
- [add] penco (2)
- [add] scrikks (2)
- [add] staedtler (2)
- [add] bic (1)
- [add] dededepraise (1)
- [add] ito (1)
- [add] mr (1)
- [add] muji (1)
- [add] pen (1)
- [add] redcircle (1)
- [add] unbranded (1)
- [add] wsd (1)
- [add] ya (1)
- [add] ystudio (1)
|
|
Tips: In general, the only data that you want analysed are those fields that will be used as a keyword search. |

Additionally, throughout this book, all Solr fields will use a copy field for text searching, rather than having Solr search on individual fields. This will allow values of non-analysed fields to be copied to this field, analysed, and queried.
The Solr Configuration File
The Solr configuration file (solrconfig.xml) with comments is over 1,300 lines long, there are two parts of the configuration file that may be of interest, namely the Query Request Handler and the Highlighting.
Query Request Handler
This is highlighted on line 795
|
789 790 791 792 793 794 795 796 797 |
<!-- A request handler that returns indented JSON by default --> <requestHandler name="/query" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <str name="wt">json</str> <str name="indent">true</str> <str name="df">text</str> </lst> </requestHandler> |
The default field that Solr will search against if no search field is set. Panl does not set the search field and relies on this default.
In the managed-schema.xml file for the mechanical pencils collection, all of the fields are copied to this text field, which can then be searched upon.
|
51 52 53 54 55 56 57 58 59 60 61 61 63 64 65 66 67 68 69 |
<copyField source="brand" dest="text" /> <copyField source="name" dest="text" /> <copyField source="mechanism_type" dest="text" /> <copyField source="nib_shape" dest="text" /> <copyField source="body_shape" dest="text" /> <copyField source="grip_type" dest="text" /> <copyField source="grip_shape" dest="text" /> <copyField source="cap_shape" dest="text" /> <copyField source="category" dest="text" /> <copyField source="nib_material" dest="text" /> <copyField source="mechanism_material" dest="text" /> <copyField source="grip_material" dest="text" /> <copyField source="body_material" dest="text" /> <copyField source="tubing_material" dest="text" /> <copyField source="clip_material" dest="text" /> <copyField source="cap_material" dest="text" /> <copyField source="colours" dest="text" /> <copyField source="variants" dest="text" /> <copyField source="description" dest="text" /> |
|
|
IMPORTANT: Panl does not include a way to set the search fields for a phrase query and relies on the default Solr field to search upon |
Highlighting
This section of the Solr managed schema file starts on line 1060 and runs for just over 100 lines; it is not included in this book for brevity. The highlighting component controls what text any highlighted words will be surrounded with when they are returned with the Solr results. This doesn't impact the Panl server in any way, however if you are going to use highlighting, then there are some important considerations in order to enable this.
If highlighting is enabled in the <panl_collection_url>.panl.properties file via setting the solr.highlight=true property, then the following rules are applied:
Highlighting requires that you have a uniqueKey defined in your schema. - In the mechanical-pencils collection, the unique key is id (mapped to the LPSE code of i)
- Panl will pass through the hl=true Solr query parameter and the hl.fl=* parameter.
- Panl will use the unified highlighter
- In the Panl Results Viewer web app, the functionality for utilising the returned highlighted results has not been implemented. The implementation is upon you, the integrator, to determine the best way to display the results.
See the Solr documentation for in-depth information:
https://solr.apache.org/guide/solr/latest/query-guide/highlighting.html
|
|
IMPORTANT: Solr will only return fields for which are indexed. I.e. fields in the managed schema file with the indexed attribute set to true. |
~ ~ ~ * ~ ~ ~